近日,2025年USENIX年度技术会议(ATC'25,The 2025 USENIX Annual Technical Conference)在美国波士顿与OSDI联合召开。作为计算机系统领域顶级的CCF-A类会议,本届ATC共收到634篇论文投稿,仅100篇成功入选,中稿率低至15.8%。其中,华为数据中心网络技术实验室与中国科学院计算技术研究所合作完成的论文——基于Compute Express Link(CXL)的解耦式机架架构DRack,成功获收录。该论文提出在机柜规模内,通过以太网与CXL总线多模式互连构建网卡池-内存池架构DRack,为解决数据中心跨机柜网络通信带宽瓶颈提供了创新方案。
图为作者张旭做线上报告
研究背景
跨机柜网络通信带宽逐渐成为
分布式计算的性能瓶颈
随着数据密集型应用的广泛部署,其计算规模已扩展至多主机、多机柜并行,并依托GPU、领域定制加速器等高性能计算单元实现高吞吐处理。这一趋势对网卡带宽及网络带宽提出更高要求,以满足机柜间数据同步的时效性需求。
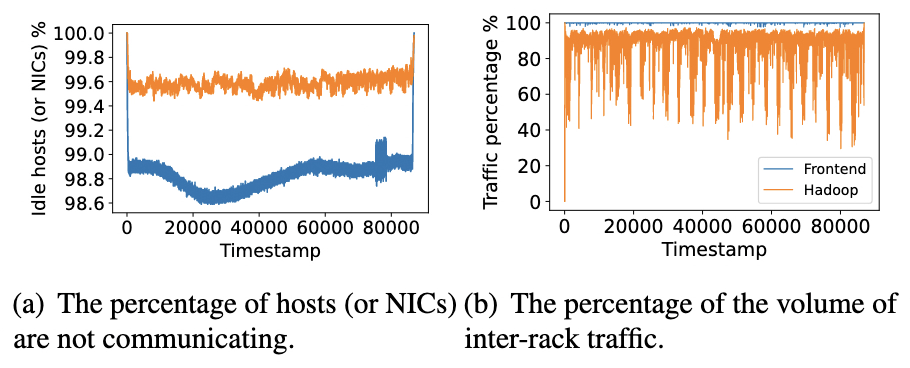
但在传统柜顶交换机(Top of Rack,ToR)架构中,主机私有网卡与机柜间核心网络常因资源超额认购(over-subscription),成为跨机柜通信的性能瓶颈。研究通过实证发现:尽管跨机柜通信流量规模大,但单个机柜内主机网卡利用率普遍偏低,核心原因有两点:一是不同主机计算负载不均衡,数据访问量差异显著;二是部分主机仅运行非分布式任务,无数据同步需求。若能实现机柜内闲置网卡资源的动态共享与灵活调度,可有效提升跨机柜通信效率。
DRack设计思路
CXL与以太网融合破解瓶颈
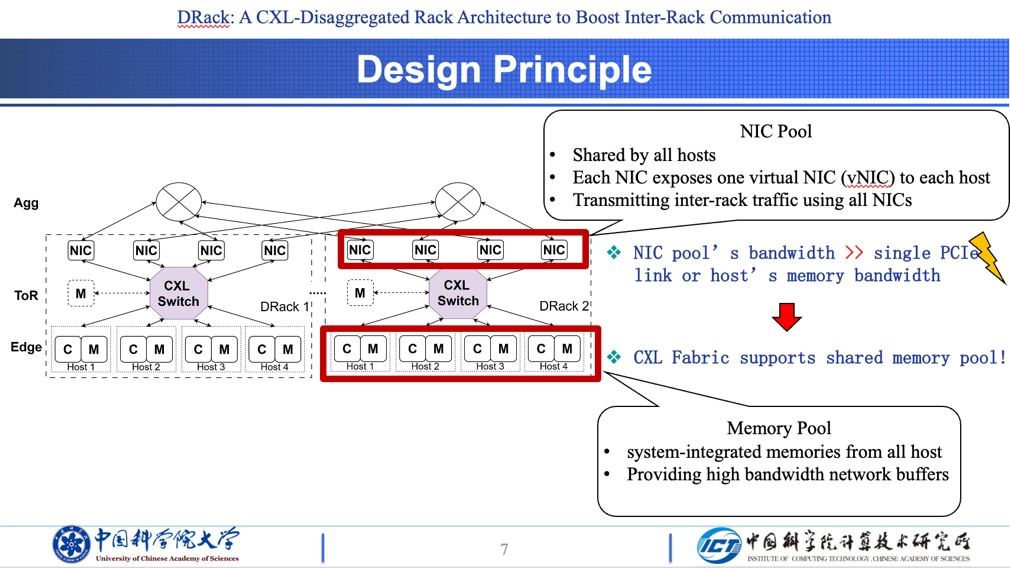
研究创新性提出DRack新型机柜架构,通过CXL总线与以太网融合,构建“网卡池-内存池”双池体系,核心设计包含三点:
网卡解耦与共享池构建:将机柜内所有网卡从主机解耦,形成集中式共享网卡池,可向单个主机提供短时聚合带宽,大幅提升网卡资源利用率
内存解耦与大带宽池构建:考虑到主机本地内存及PCIe链路带宽远低于网卡池总带宽,单一主机难以充分利用网卡资源,DRack进一步解耦主机内存,构建聚合读写带宽超越网卡池的机柜级内存池,支持网卡池向多内存设备并行读写数据。
内存语义直访优化:允许主机处理器或加速器在计算过程中,通过内存语义直接读写内存池数据,无需先经DMA将数据迁移至本地内存,减少数据传输环节,提升效率。
选择CXL互连实现DRack架构,核心在于其两大特性与设计需求高度契合:一是CXL2.0标准通过CXL交换机支持内存与IO设备池化,CXL3.0进一步实现机柜级内存共享;二是CXL支持CXL.mem协议(内存语义),可满足主机直访内存池的需求。
通过上述设计,DRack不仅有效缓解传统ToR架构的跨机柜通信瓶颈,其更优的通信效率还能为现有任务调度算法(如 Crux@Sigcomm24)提供有力补充。相较于现有方案,DRack采用静态架构设计,无需应对可重构性与流量预测的复杂性,也无需额外增置硬件;同时可通过向CXL互连架构接入更多内存、网卡设备,实现系统灵活扩展。
实验效果:多场景性能显著提升
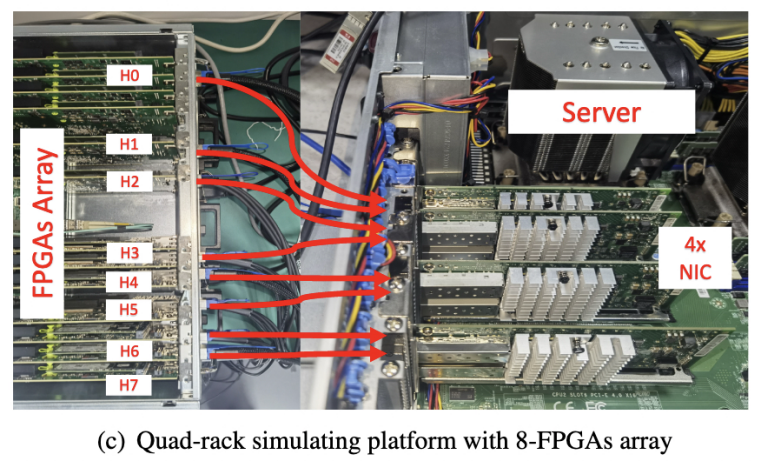
鉴于目前尚无商业化CXL3.0产品,研究团队开发了原型验证系统,用于模拟四机柜DRack架构:每个机柜配备2个定制化 MPSoC FPGA(模拟计算主机,集成四核CPU、双通道内存、四个光纤端口),CPU通过HP/HPC端口将内存总线信号传至FPGA侧,并实现类CXL协议软IP;同一机柜的2个FPGA连接服务器双端口网卡,基于DPDK技术在服务器上仿真网卡池与CXL互连功能。
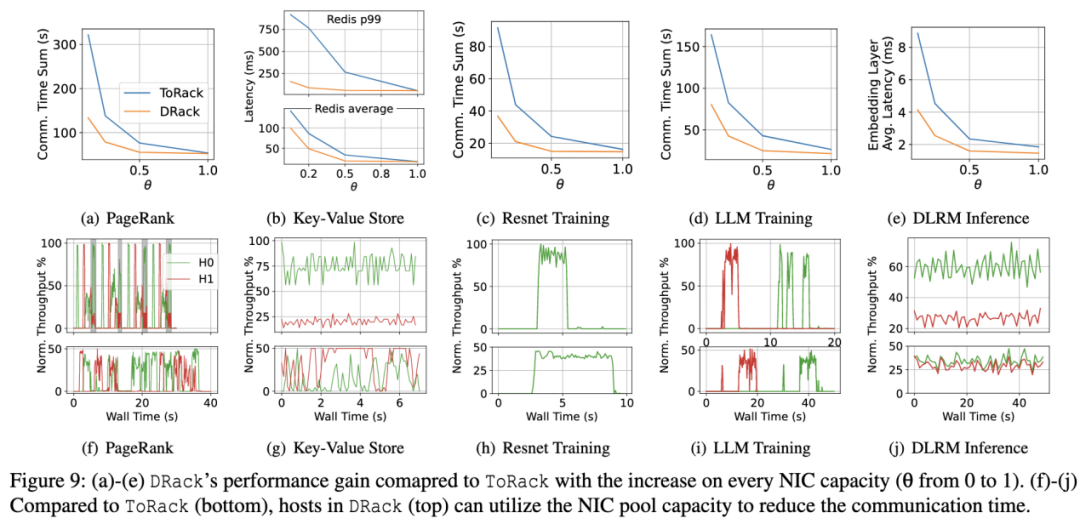
测试结果显示,在DNN训练、图计算(数据密集型)及键值存储(延迟敏感型)等典型应用场景中,DRack较传统ToR架构平均降低37.3%的数据同步时间。此外,网卡池带宽利用率表现优异:单个主机可充分利用带宽,两台主机同时通信时,能根据流量大小动态共享资源,总体带宽利用率接近1。
技术突破意义
获国际认可,夯实创新地位
DRack相关技术有望与业界scaleup方案形成深度协同,整体提升高性能计算与分布式系统能力。在面向大规模人工智能计算场景时,该架构能够显著增强基于万卡、千机柜的大语言模型训练与推理任务的执行效率,降低通信开销、提升资源利用率。同时,在传统分布式应用(如图计算、内存键值存储(如Memcached))等系统中,该技术也可有效优化通讯表现与资源利用率,进一步提升整体系统吞吐与响应性能,为下一代数据中心基础设施构建提供可扩展、高效率的架构支撑。
此次DRack相关论文获USENIX ATC收录,不仅意味着华为与中国科学院计算技术研究所在CXL技术与数据中心机柜架构融合领域的探索,得到国际顶级学术界的高度认可,更标志着华为在数据中心网络领域的又一重大突破。
红腾网提示:文章来自网络,不代表本站观点。